Performance of vision-language models on EuraGovExam. All numbers are accuracy (%).
Overview
EuraGovExam is a multilingual, image-only benchmark built from real civil service exams across five Eurasian regions, testing vision-language models on layout-aware, instruction-free reasoning in high-stakes, culturally grounded settings.
We introduce EuraGovExam, a comprehensive multilingual multimodal benchmark designed to evaluate vision-language models on real-world government examination questions across Eurasian countries. Our benchmark comprises 8,000 questions spanning 17 subject areas from official civil service examinations in India, the European Union, Japan, Taiwan, and South Korea.
Unlike existing benchmarks that focus primarily on English or academic contexts, EuraGovExam captures the diverse linguistic, cultural, and administrative knowledge required for government positions across different nations. We evaluate 28 state-of-the-art vision-language models and reveal significant performance gaps across languages and domains, highlighting the need for more culturally-aware multimodal AI systems.
Performance of vision-language models on EuraGovExam. All numbers are accuracy (%).
| Rank | Model | Overall | India | EU | Japan | Taiwan | S.Korea |
|---|---|---|---|---|---|---|---|
| 🥇 | Gemini-2.5-pro | 86.99 | 69.23 | 88.08 | 87.59 | 95.51 | 91.12 |
| 🥈 | GPT-5 | 85.8 | 68.35 | 83.87 | 87.5 | 94.8 | 91.17 |
| 🥉 | o3 | 84.26 | 68.64 | 84.49 | 82.37 | 93.72 | 90.06 |
| 4 | o4-mini | 79.4 | 63.38 | 76.95 | 82.52 | 92.29 | 82.49 |
| 5 | Gemini-3-flash | 75.28 | 51.7 | 89.54 | 56.69 | 97.31 | 84.5 |
| 6 | GPT-5.2 | 69.94 | 53.46 | 68.05 | 73.83 | 78.67 | 73.09 |
See full leaderboard with all 28 models: Detailed Leaderboard →
EuraGovExam contains 8,000 multiple-choice questions sourced from official civil service examinations across five Eurasian regions: South Korea (2,448 questions), Japan (2,048 questions), European Union (1,920 questions), India (1,024 questions), and Taiwan (560 questions). The questions span 17 academic and professional domains including Law, Administration, Economics, History, Geography, Mathematics, Physics, Chemistry, Biology, Earth Science, Medicine, Computer Science, Engineering, Language, Philosophy, Psychology, and Politics.
All questions are presented in their original image format without text extraction, preserving authentic layout complexity including mathematical equations, scientific diagrams, tables, and multilingual scripts (Korean, Japanese, Traditional Chinese, Hindi, Catalan, and other regional languages). This image-only format tests vision-language models on real-world document understanding rather than pre-processed text.
The dataset was collected from publicly available government examination archives and official education portals. Each question includes the original exam image, correct answer, subject classification, and regional metadata. Questions were sampled to ensure balanced representation across difficulty levels and content domains, reflecting the authentic distribution of civil service exam topics. The complete dataset is available on HuggingFace.
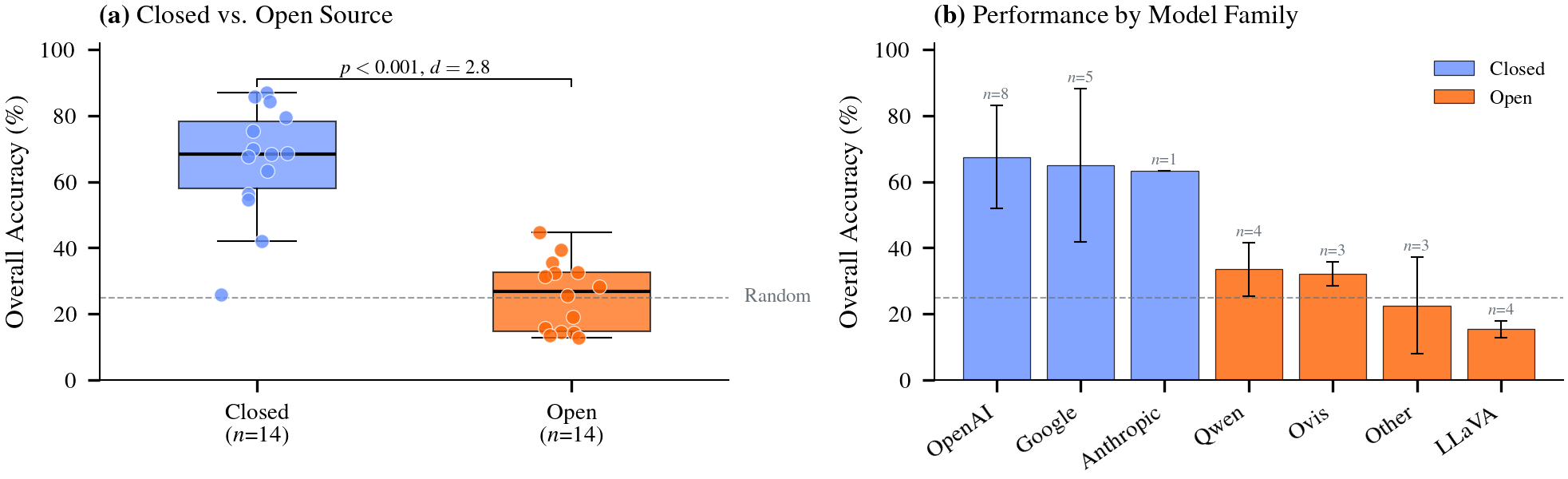
We evaluated 28 state-of-the-art vision-language models on EuraGovExam. The best model (Gemini-2.5-pro) achieves 86.99% overall accuracy, while smaller models struggle to reach 50%. This wide performance gap reveals that government examination questions pose substantial challenges even for frontier VLMs, requiring both strong visual parsing and domain-specific reasoning capabilities.
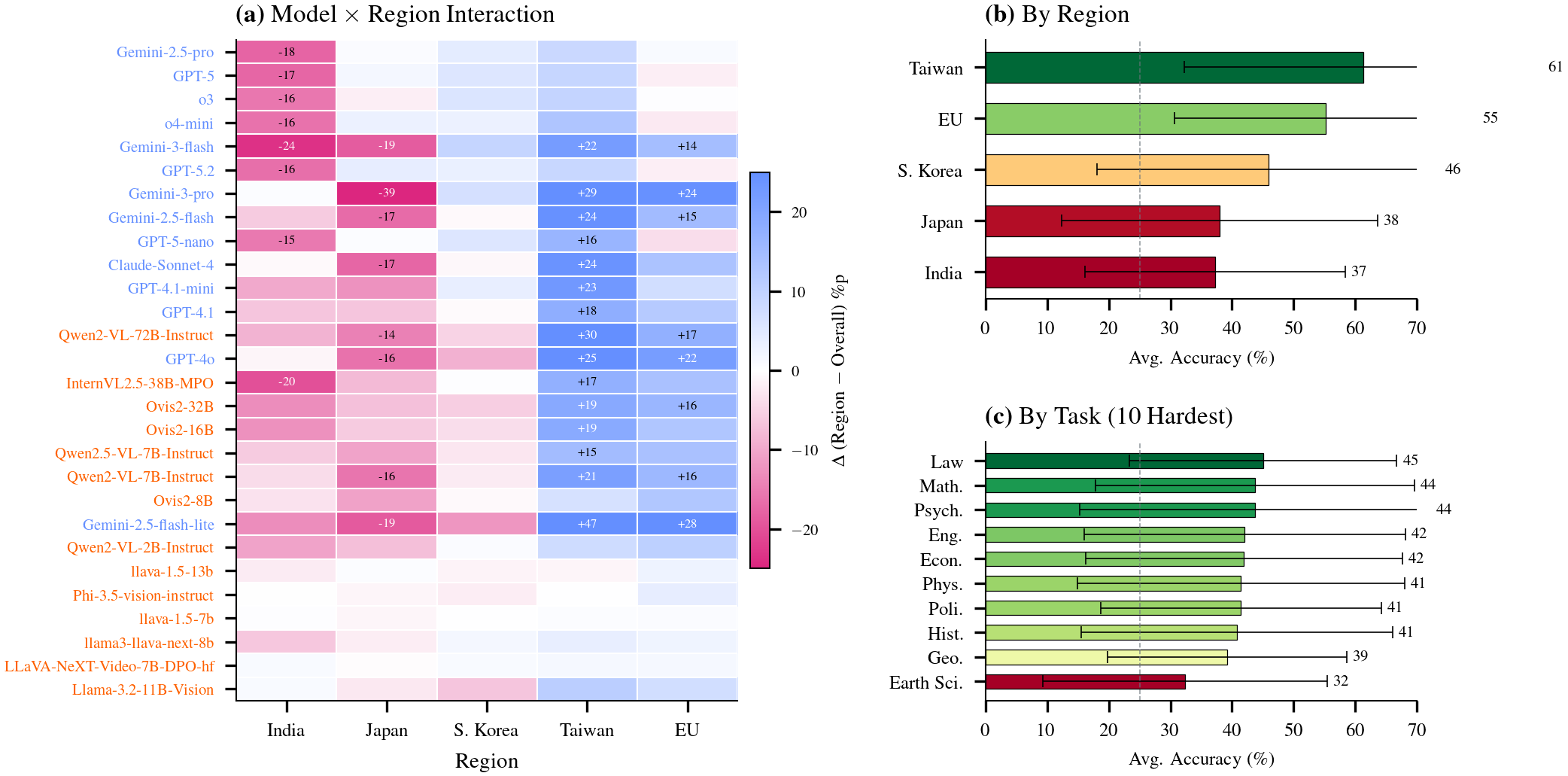
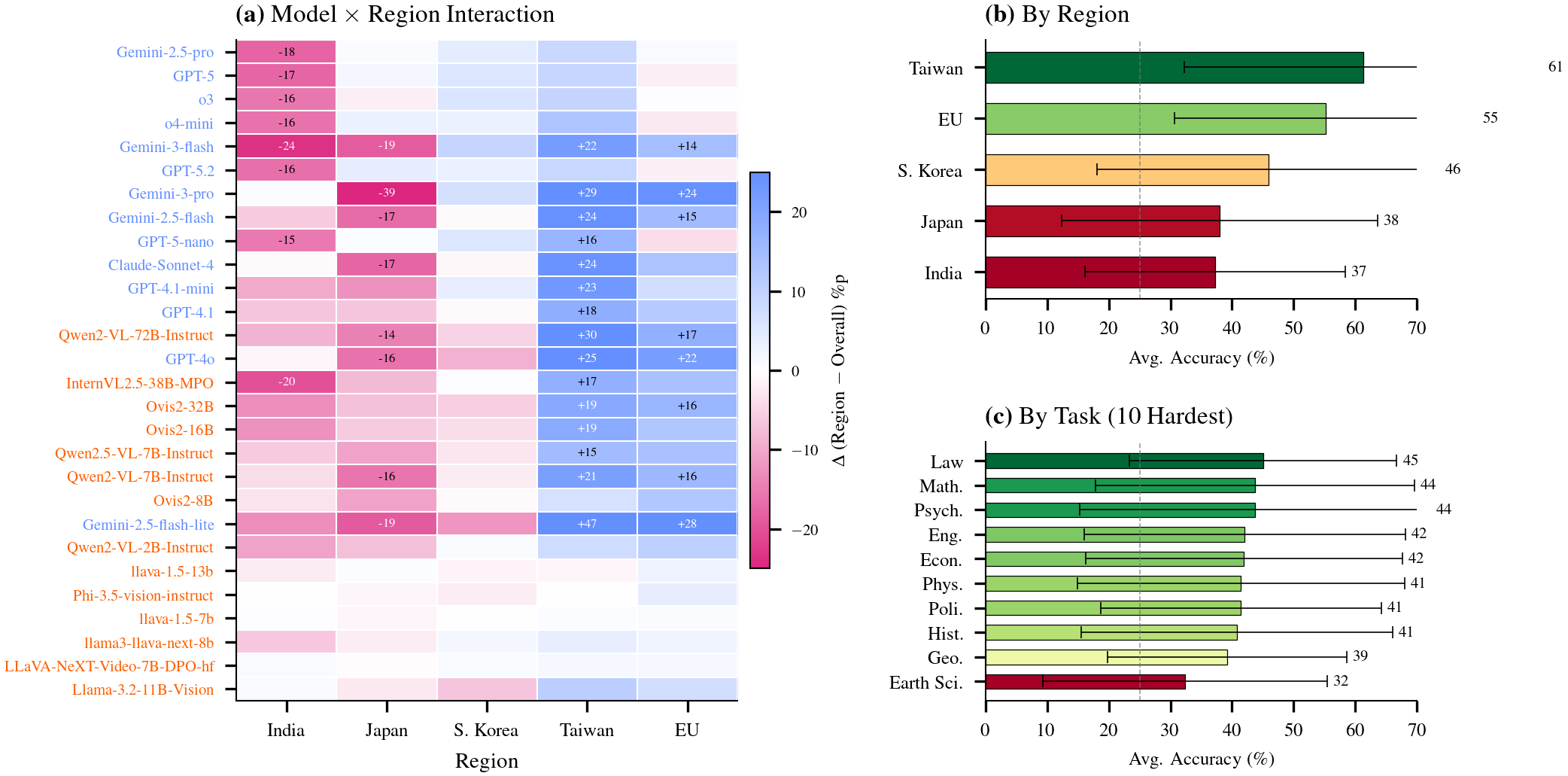
Models exhibit stark performance differences across regions, with accuracy varying by up to 40 percentage points for the same model. Taiwan questions achieve the highest average accuracy (73.2%), while India questions prove most challenging (49.8%). These disparities stem from linguistic barriers (non-Latin scripts, specialized terminology), cultural context requirements (region-specific regulations, historical knowledge), and imbalanced training data distribution. Even top-performing models struggle with questions in Hindi, Traditional Chinese, and domain-specific Catalan or Korean administrative language.
Representative examples showing where and why models fail on government examinations.
Taiwan · Biology

Question: Traditional Chinese anatomy question asking about the location of the temporal bone (顳骨).
Model answer (GPT-4.1): Incorrectly identified the cranial bone (顱骨) due to misreading the similar-looking character 顳 as 顱.
Why it failed: Visual parsing error on complex Traditional Chinese characters combined with insufficient verification against anatomical context. The model's OCR component confused visually similar radicals in medical terminology.
Japan · Physics
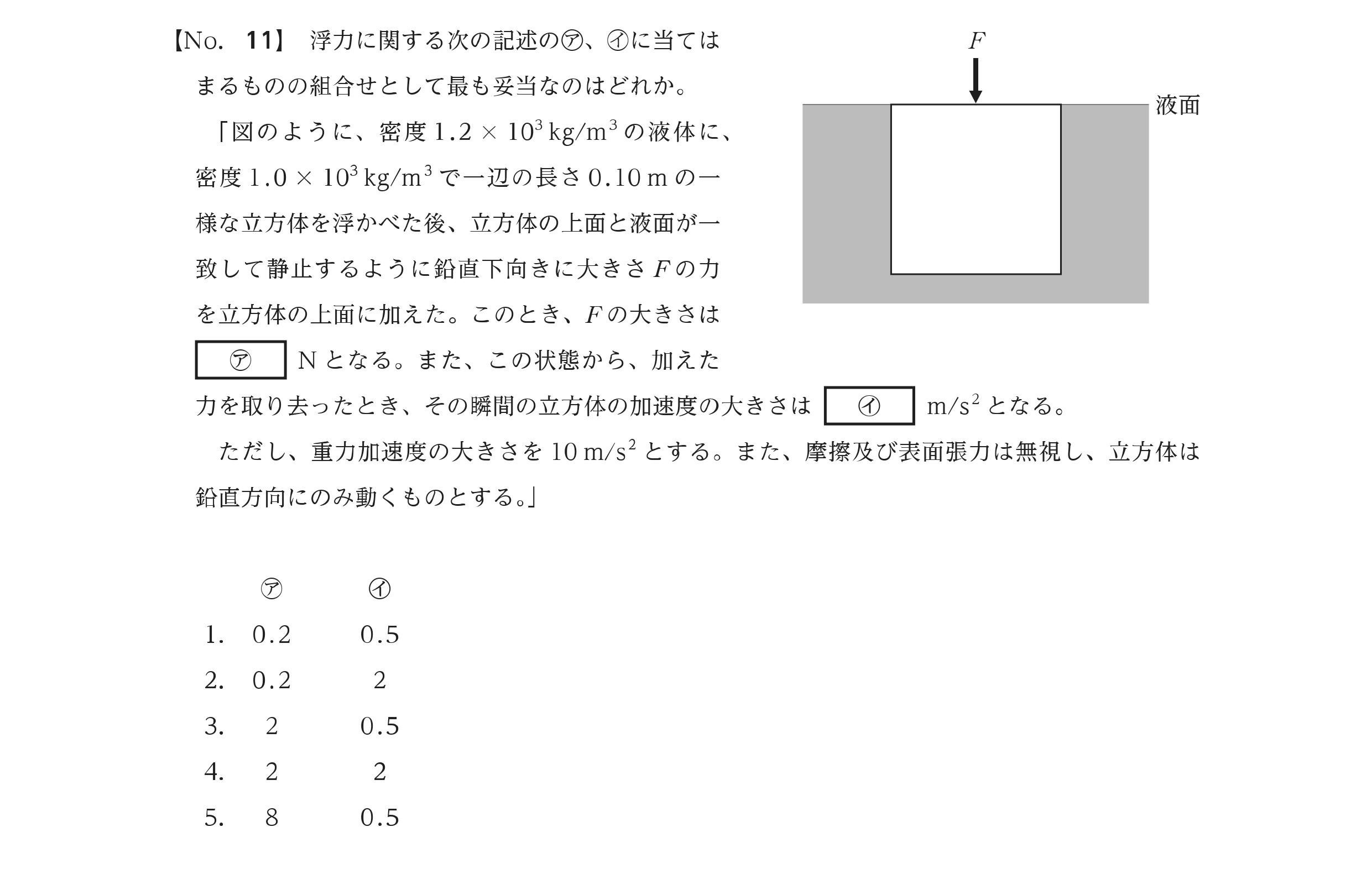
Question: Calculate the time for a projectile to reach maximum height on an inclined plane.
Model answer (o4-mini): Applied standard projectile motion formula for flat ground, ignoring the incline angle.
Why it failed: The model correctly parsed the Japanese text and equations but failed to decompose gravity into incline-parallel and incline-perpendicular components. It applied memorized physics formulas without adapting to the tilted reference frame, demonstrating reasoning failure despite accurate visual parsing.
Japan · Engineering

Question: Determine the logic function of a CMOS circuit from its transistor diagram.
Model answer (Qwen2-VL-72B): Misidentified PMOS and NMOS transistors, resulting in inverted logic function.
Why it failed: Compound failure combining visual parsing errors (confusing PMOS/NMOS symbols) and gaps in digital circuit domain knowledge. The model struggled to map circuit topology to boolean logic, revealing limitations in both diagram understanding and specialized engineering knowledge.
South Korea · Administration

Question: Classify a book according to Korean Decimal Classification (KDC) rules based on its description.
Model answer (Claude-Sonnet-4): Selected category based on surface-level keywords rather than hierarchical rule application.
Why it failed: Despite correctly parsing the Korean table structure, the model failed to apply KDC's hierarchical classification rules systematically. It relied on pattern matching instead of procedural reasoning, exposing weaknesses in rule-based decision making.
EU · Law

Question: Catalan building code question about specific height restrictions for residential buildings.
Model answer (Claude-Sonnet-4): Applied general European building standards instead of Catalonia-specific regulations.
Why it failed: Lack of region-specific legal knowledge. The model attempted to reason from general principles but missed the domain-specific regulatory context required for Catalan ordinances, highlighting the benchmark's ability to expose gaps in localized expertise.
South Korea · Biology
Question: Interpret a biological process diagram showing cellular respiration with Korean labels and equations.
Model answer (Multiple models): Misread Korean scientific terminology (e.g., 미토콘드리아 as different organelles) and failed to integrate diagram arrows with textual explanations.
Why it failed: Compound failure: OCR errors on Korean scientific terms combined with difficulty maintaining coherent reasoning across visual (diagram) and textual (equations) modalities. Models struggled with multimodal integration when both components contained domain-specific foreign language content.
Taiwan · Medicine

Question: Medical policy analysis question about Taiwan's National Health Insurance reimbursement criteria in Traditional Chinese.
Model answer (Phi-3.5-Vision): Identified individual policy components correctly but drew incorrect conclusion about combined eligibility criteria.
Why it failed: Multi-step reasoning failure. Despite accurate text parsing, the model could not chain inferences across multiple regulatory clauses to determine final eligibility. Required understanding both the policy's logical structure and healthcare domain context.
Japan · Mathematics

Question: Geometric proof involving angle relationships in Japanese notation with algebraic equations.
Model answer (Llama-3.2-11B): Misparsed the geometric diagram, confusing similar angles and applying incorrect transformations.
Why it failed: Visual grounding failure compounded by reasoning errors. The model struggled to accurately extract spatial relationships from the diagram and then applied flawed mathematical transformations. Demonstrates challenges in visual-symbolic reasoning for spatial problems in non-Latin scripts.